import java.util.*;
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int n = sc.nextInt();
int m = sc.nextInt();
int[][] num = new int[n][m];
for (int i=0; i<n; i++) {
String s = sc.next();
for (int j=0; j<m; j++) {
num[i][j] = s.charAt(j) - '0'; // char형을 int 형으로 바꾸는 방법
}
}
// 비트마스크 - 브루트포스
// 각 칸을 가로로 놓을지 세로로 놓을지 모든 경우의 수를 확인
int ans = 0;
for (int i=0;i<(1<<(n*m));i++) {
int sum = 0;
// 가로로 놓는 경우
for (int j=0;j<n;j++) {
int cur = 0; // 현재 이어진 가로칸들로 구성된 수
for (int k=0;k<m;k++) {
int index = j*m+k; // 2차원 배열을 1차원 배열로 보았을 때, i행 j열은 앞에 i*m+(j-1)개의 원소들이 있기 때문
if ((i&(1<<index)) == 0) { // 가로이면
cur = cur*10 + num[j][k];
} else {
sum += cur;
cur = 0;
}
}
sum+=cur;
}
// 세로로 놓는 경우
for (int j=0;j<m;j++) {
int cur = 0;
for (int k=0;k<n;k++) {
int index = k*m+j;
if ((i&(1<<index)) != 0) { // 세로이면
cur = cur*10 + num[k][j];
} else {
sum += cur;
cur = 0;
}
}
sum += cur;
}
ans = Math.max(ans, sum);
}
System.out.println(ans);
}
}
import java.util.*;
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int n = sc.nextInt();
int s = sc.nextInt();
int[] num = new int[n];
for (int i=0;i<n;i++) {
num[i] = sc.nextInt();
}
// 비트마스크 - 브루트포스
// 만들 수 있는 부분 집합들의 경우의 수들을 정수로 표현했음 (공집합 제외)
// 1부터 2^n까지
int cnt = 0; // 부분 수열의 합이 같은 경우의 수를 세기 위한 변수
for (int i=1;i<(1<<n);i++) { // 만들 수 있는 모든 부분 집합들에 대해 반복
int sum = 0;
for (int j=0;j<n;j++) {
if((i&(1<<j)) != 0) { // 정수로 표현한 부분 집합 i에 j가 들어있다면
sum += num[j];
}
}
if (sum == s) { // 해당 부분집합 i에 들어있는 모든 정수들을 더한 값이 s와 같으면
cnt+=1;
}
}
System.out.println(cnt);
}
}
cf) not의 비트연산은 자료형에 따라 결과가 달라진다. ex) 8bit 자료형, 32비트 자료형의 결과가 다르다. A = 1010011이면 ~A = 10101100 (8비트) ~A = 11111111 11111111 11111111 10101100 (32비트)
#shift 비트연산 : right shift(>>), left shift(<<) ex)
1<<4 = 10000 (16) 1010 >> 3 = 1 (1)
A<<B는 A*(2^B)와 같고 A>>B는 A/(2^B)와 같다.
# 비트 연산 - 정수를 이용해서 집합을 나타낼 수 있다. {1, 3, 4, 5, 9}가 있다면 1을 2^1, 3을 2^3, 4를 2^4, 5를 2^5, 9를 2^9로 놓고 모두 더한 값인 570으로 해당 집합을 나타낼 수 있다. {1, 3, 4, 5, 9} = 2^1 + 2^3 + 2^4 + 2^5 + 2^9 = 570
장점 : 정수 1개로 집합을 표현할 수 있으므로 공간적으로 효율적이다.
cf) 비트마스크를 사용하기 위해서는 사용하려는 수가 최대 몇개가 있는지 알아야 한다. (int 자료형의 경우 32비트이기 때문에 2^32가 넘는 수를 사용하는 집합은 표현할 수 없음)
비트마스크 사용 시에는 n개의 수를 0부터 n-1로 변환하여 사용하는 것이 좋다.
(1~n으로 사용하면 0~n-1에서 1만큼 left shift한 것인데 이는 곧 *2를 한 것으로
공간적으로나 시간적으로나 2배가 소요된다.)
# 비트마스크에서 수를 포함하는지 검사하는 방법 ex) {1, 3, 4, 5, 9} = 570 = 1000111010 2가 포함되어 있는지 검사 -> 1000111010에 2^2자리를 포함하고 있는지 확인해야 한다. 570 & 2^2 = 570 & (1<<2) = 0 1. 1<<2 : 2^2자리를 1로 설정 2. 570 & (1<<2) : 2^2자리끼리 and 연산을 했을 때, 결과가 2^2이면 570도 2^2자리가 1인 것이고 결과가 0이면 570은 2^2자리가 0인 것이다.
# 비트마스크에서 수 추가 연산 ex) {1, 3, 4, 5, 9} = 570 = 1000111010 추가하려는 수의 비트 위치를 1로 바꾸어주면 된다. 2를 추가하려면 570 | (1<<2) = 574 1000111010 에 100을 or 연산한 것으로 2^2의 자리가 무조건 1이 된다. 결과 : 1000111110
같은 것을 또 추가한다 하더라도 연산 결과가 같기 때문에 중복처리 가능 (or연산의 특징)
# 비트마스크에서 수 제거 연산 제거하려는 수의 비트 위치를 0으로 바꾸는 것이다. 1을 제거하려면 570 & ~(1<<1) = 568 1. ~(1<<1) 은 2^1자리만 0인 2진수를 만들어준다 2. 570 & ~(1<<1) 은 570에서 1번에서 만든 2진수와 and연산을 수행하므로 해당 2진수에서 0인 2^1자리를 570에서도 0으로 만든다.
# 비트마스크에서 수 토글 연산 1을 토글하기 570 ^ (1<<1) xor 비트 연산을 사용 1^1 = 0, 1^0 또는 0^1 = 1이 되는 특성 사용 570의 해당 자리가 1이였다면 1^1 연산이 되어 0으로 토글되고 해당 자리가 0이였다면 1^0 연산이 되어 1로 토글된다.
# 비트마스크의 전체 집합 = (1<<N)-1 = 2^N -1 개 # 공집합 = 0 (모든 수들이 0 -> 결과 값도 0이 됨)
# 비트연산 정리 - i 추가 : S | (1<<i) - i 존재 검사 : S & (1<<i) - i 제거 : S & ~(1<<i) - i를 토글 : S ^ (1<<i)
# 비트마스크를 언제 사용하는가? 문제에 할 수 있는 것이 n개가 있고, 이때 일부를 선택해서 할 수 있을 때 모든 경우를 만드는 경우
MySQL)테이블에 데이터 추가하기, 보기 (INSERT, SELECT, UPDATE, DELETE)
SQL의 CRUD
- Create, Read, Update, Delete
테이블은 만들어져 있다고 할 때, 아래와 같이 데이터를 추가해보자.
먼저 테이블이 어떤 형식으로 만들어져 있는지 확인한다.
# DESC
mysql> DESC topic;
+-------------+--------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------------+--------------+------+-----+---------+----------------+
| id | int | NO | PRI | NULL | auto_increment |
| title | varchar(100) | NO | | NULL | |
| description | text | YES | | NULL | |
| created | datetime | NO | | NULL | |
| author | varchar(15) | YES | | NULL | |
| profile | varchar(200) | YES | | NULL | |
+-------------+--------------+------+-----+---------+----------------+
describe을 뜻하는 명령어 DESC를 통해 topic 테이블에 대한 정보를 확인한다.
# INSERT
mysql> INSERT INTO topic (title, description, created, author, profile) VALUES('MySQL', 'MySQL is ...', NOW(), 'Kim', 'developer');
MySQL을 title로 하는 데이터 1개를 추가하기 위해 위와 같은 명령어를 실행한다.
id는 auto_increment로 설정되어 있으므로 직접 추가하지 않아도 자동으로 오름차순으로 추가된다.
INSERT INTO 명령어를 통해 topic이라는 테이블의 각 열에 대해 VALUES에 들어가는 데이터들을 추가한다.
이때 NOW()는 datatime 형식인 created 열에 추가되는 데이터를 위한 함수인데, 데이터를 추가하는 시점의 날짜, 시각을 자동으로 입력해주는 기능을 한다.
# SELECT
mysql> SELECT * FROM topic;
+----+------------+-------------------+---------------------+--------+-----------+
| id | title | description | created | author | profile |
+----+------------+-------------------+---------------------+--------+-----------+
| 1 | MySQL | MySQL is ... | 2020-08-07 18:04:06 | Kim | developer |
| 2 | Oracle | Oracle is ... | 2020-08-07 18:06:08 | Kim | developer |
| 3 | SQL Server | SQL Server is ... | 2020-08-07 18:07:39 | Lee | Developer |
| 4 | PostgreSQL | PostgreSQL is ... | 2020-08-07 18:08:36 | Lee | Developer |
| 5 | MongoDB | MongoDB is ... | 2020-08-07 18:09:34 | Park | student |
+----+------------+-------------------+---------------------+--------+-----------+
5 rows in set (0.00 sec)
또한 SELECT * FROM 명령어를 통해 topic 테이블에 있는 데이터들을 모두 확인할 수 있다.
여기서 SELECT *은 모든 데이터를 선택한다는 것을 뜻하고 (*은 주로 모든 것을 포함하는 의미),
FROM topic은 topic 테이블에서 앞 명령어를 수행할 것이라는 의미를 갖는다.
/* SELECT 뒤에 원하는 열들의 이름을 넣는 것으로
열람하고 싶은 열들로 접근해서 해당 열들의 정보만 확인도 가능하다.*/
mysql> SELECT id, title, created, author FROM topic;
+----+------------+---------------------+--------+
| id | title | created | author |
+----+------------+---------------------+--------+
| 1 | MySQL | 2020-08-07 18:04:06 | Kim |
| 2 | Oracle | 2020-08-07 18:06:08 | Kim |
| 3 | SQL Server | 2020-08-07 18:07:39 | Lee |
| 4 | PostgreSQL | 2020-08-07 18:08:36 | Lee |
| 5 | MongoDB | 2020-08-07 18:09:34 | Park |
+----+------------+---------------------+--------+
5 rows in set (0.00 sec)
/* WHERE 명령어를 통해 특정 데이터에 해당하는 데이터들만 확인하는 것도 가능하다.
밑의 예시의 경우, author가 kim인 데이터들만 가져온다. */
mysql> SELECT id, title, created, author FROM topic WHERE author = 'kim';
+----+--------+---------------------+--------+
| id | title | created | author |
+----+--------+---------------------+--------+
| 1 | MySQL | 2020-08-07 18:04:06 | Kim |
| 2 | Oracle | 2020-08-07 18:06:08 | Kim |
+----+--------+---------------------+--------+
2 rows in set (0.00 sec)
/* ORDER BY 명령어를 통해 데이터를 오름차순 또는 내림차순으로도 가져올 수 있다.
DESC는 descend의 약자로 내림차순으로 데이터를 가져온다.
ASC는 ascend의 약자로 오름차순으로 데이터를 가져오며 이가 default이다. */
mysql> SELECT id, title, created, author FROM topic WHERE author = 'kim' ORDER BY id DESC;
+----+--------+---------------------+--------+
| id | title | created | author |
+----+--------+---------------------+--------+
| 2 | Oracle | 2020-08-07 18:06:08 | Kim |
| 1 | MySQL | 2020-08-07 18:04:06 | Kim |
+----+--------+---------------------+--------+
2 rows in set (0.00 sec)
mysql> SELECT * FROM topic ORDER BY id DESC;
+----+------------+-------------------+---------------------+--------+-----------+
| id | title | description | created | author | profile |
+----+------------+-------------------+---------------------+--------+-----------+
| 5 | MongoDB | MongoDB is ... | 2020-08-07 18:09:34 | Park | student |
| 4 | PostgreSQL | PostgreSQL is ... | 2020-08-07 18:08:36 | Lee | Developer |
| 3 | SQL Server | SQL Server is ... | 2020-08-07 18:07:39 | Lee | Developer |
| 2 | Oracle | Oracle is ... | 2020-08-07 18:06:08 | Kim | developer |
| 1 | MySQL | MySQL is ... | 2020-08-07 18:04:06 | Kim | developer |
+----+------------+-------------------+---------------------+--------+-----------+
5 rows in set (0.00 sec)
/* LIMIT 명령어를 통해 해당 조건에 부합하는 데이터를 순서에 맞추어 일부만 가져오는 것도 가능하다.
아래의 예시는 해당 조건에 맞는 데이터를 1개만 가져오는 명령어이다. */
mysql> SELECT id, title, created, author FROM topic WHERE author = 'kim' ORDER BY id DESC LIMIT 1;
+----+--------+---------------------+--------+
| id | title | created | author |
+----+--------+---------------------+--------+
| 2 | Oracle | 2020-08-07 18:06:08 | Kim |
+----+--------+---------------------+--------+
1 row in set (0.00 sec)
# UPDATE
아래 예시는 topic 테이블에서 특정 데이터를 수정하는 예시이다.
이를 위해 UPDATE 명령어가 사용되었다.
mysql> SELECT * FROM topic;
+----+------------+-------------------+---------------------+--------+-----------+
| id | title | description | created | author | profile |
+----+------------+-------------------+---------------------+--------+-----------+
| 1 | MySQL | MySQL is ... | 2020-08-07 18:04:06 | Kim | developer |
| 2 | Oracle | Oracle is ... | 2020-08-07 18:06:08 | Kim | developer |
| 3 | SQL Server | SQL Server is ... | 2020-08-07 18:07:39 | Lee | Developer |
| 4 | PostgreSQL | PostgreSQL is ... | 2020-08-07 18:08:36 | Lee | Developer |
| 5 | MongoDB | MongoDB is ... | 2020-08-07 18:09:34 | Park | student |
+----+------------+-------------------+---------------------+--------+-----------+
5 rows in set (0.00 sec)
위 테이블에서 author가 Park인 데이터를 Kim으로, 그리고 profile 또한 developer로 고쳐주려고 한다.
UPDATE topic SET author = 'Kim', profile = 'developer' WHERE id = 5;
topic 테이블의 데이터를 업데이트 하는데 id가 5인 데이터의 author를 'Kim', profile을 'developer'로 바꾼다는 것이다.
위 명령어에서 주의할 점은 바로 WHERE이다.
WHERE를 빠뜨리고 위 명령어를 실행하면 topic 테이블의 모든 데이터들이 SET으로 설정한 데이터로 모두 수정되기 때문이다.
mysql> UPDATE topic SET author = 'Kim', profile = 'developer' WHERE id = 5;
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> SELECT * FROM topic;
+----+------------+-------------------+---------------------+--------+-----------+
| id | title | description | created | author | profile |
+----+------------+-------------------+---------------------+--------+-----------+
| 1 | MySQL | MySQL is ... | 2020-08-07 18:04:06 | Kim | developer |
| 2 | Oracle | Oracle is ... | 2020-08-07 18:06:08 | Kim | developer |
| 3 | SQL Server | SQL Server is ... | 2020-08-07 18:07:39 | Lee | Developer |
| 4 | PostgreSQL | PostgreSQL is ... | 2020-08-07 18:08:36 | Lee | Developer |
| 5 | MongoDB | MongoDB is ... | 2020-08-07 18:09:34 | Kim | developer |
+----+------------+-------------------+---------------------+--------+-----------+
5 rows in set (0.00 sec)
# DELETE
DELETE 명령어를 통해 테이블에서 특정 데이터를 지울 수 있다.
그러나 데이터를 삭제하는 것인만큼 신중하게 수행해야 한다.
id 6번 데이터로 지우기 위한 더미 데이터를 만들어서 INSERT해주었다.
해당 데이터를 지우는 명령어는
DELETE FROM topic WHERE id = 6;
으로 topic 테이블에서 id가 6인 데이터를 지우는 작업을 수행한다.
mysql> SELECT * FROM topic;
+----+------------+-------------------+---------------------+--------+-----------+
| id | title | description | created | author | profile |
+----+------------+-------------------+---------------------+--------+-----------+
| 1 | MySQL | MySQL is ... | 2020-08-07 18:04:06 | Kim | developer |
| 2 | Oracle | Oracle is ... | 2020-08-07 18:06:08 | Kim | developer |
| 3 | SQL Server | SQL Server is ... | 2020-08-07 18:07:39 | Lee | Developer |
| 4 | PostgreSQL | PostgreSQL is ... | 2020-08-07 18:08:36 | Lee | Developer |
| 5 | MongoDB | MongoDB is ... | 2020-08-07 18:09:34 | Kim | developer |
| 6 | temp | Temp is null... | 2020-08-07 19:07:11 | null | null |
+----+------------+-------------------+---------------------+--------+-----------+
6 rows in set (0.00 sec)
mysql> DELETE FROM topic WHERE id = 6;
Query OK, 1 row affected (0.00 sec)
mysql> SELECT * FROM topic;
+----+------------+-------------------+---------------------+--------+-----------+
| id | title | description | created | author | profile |
+----+------------+-------------------+---------------------+--------+-----------+
| 1 | MySQL | MySQL is ... | 2020-08-07 18:04:06 | Kim | developer |
| 2 | Oracle | Oracle is ... | 2020-08-07 18:06:08 | Kim | developer |
| 3 | SQL Server | SQL Server is ... | 2020-08-07 18:07:39 | Lee | Developer |
| 4 | PostgreSQL | PostgreSQL is ... | 2020-08-07 18:08:36 | Lee | Developer |
| 5 | MongoDB | MongoDB is ... | 2020-08-07 18:09:34 | Kim | developer |
+----+------------+-------------------+---------------------+--------+-----------+
5 rows in set (0.00 sec)
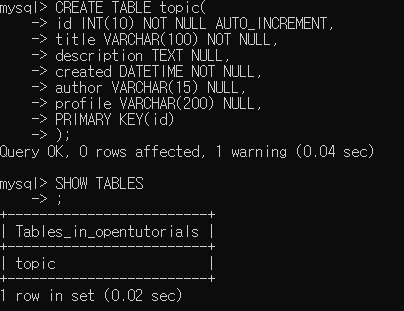
CREATE TABLE topic(
-> id INT(10) NOT NULL AUTO_INCREMENT,
-> title VARCHAR(100) NOT NULL,
-> description TEXT NULL,
-> created DATETIME NOT NULL,
-> author VARCHAR(15) NULL,
-> profile VARCHAR(200) NULL,
-> PRIMARY KEY(id)
-> );
위 코드를 통해 만들 수 있다.
각 코드별로 주석으로 설명을 달아주면 아래와 같다.
CREATE TABLE topic( /* topic이라는 이름의 테이블을 만든다.*/
-> id INT(10) NOT NULL AUTO_INCREMENT, /* 첫번째 열의 이름은 id이고 정수형의 데이터를 받으며 10자리까지 출력한다. 해당 데이터는 반드시 포함되어야하고 누락시키면 자동으로 이전 데이터 기준 오름차순으로 넣어준다*/
-> title VARCHAR(100) NOT NULL, /* 두번째 열의 이름은 title이고 100글자로 보여준다, 이 열의 데이터 역시 누락되어서는 안된다.*/
-> description TEXT NULL, /* description 이름의 열을 추가한다. 들어가는 데이터는 TEXT 타입이며, 반드시 입력될 필요는 없다.*/
-> created DATETIME NOT NULL, /* created 이름의 열을 추가한다. DATETIME 타입으로 데이터을 보여주며 누락되어서는 안된다.*/
-> author VARCHAR(15) NULL, /* author 이름의 열을 추가한다. 15글자로 보여주며, 누락되어도 된다*/
-> profile VARCHAR(200) NULL, /* profile이름의 열을 추가한다. 200글자로 보여주며, 누락되어도 된다*/
-> PRIMARY KEY(id) /* id 데이터 타입을 PRIMARY KEY로 한다.
-> );
cf) 명령어 끝에 세미콜론을 붙이지 않고 enter를 누르면 명령어가 처리되지 않고 다음 행에 이어서 명령어를 작성하게 된다.
INT는 정수형을 받는 데이터 타입이다.
NOT NULL은 해당 열의 데이터는 반드시 입력되어야 한다는 것을 의미한다.
위의 테이블을 예시로 보았을 때 title은 반드시 필요한 데이터이므로 NOT NULL로 열을 추가하여 해당 데이터가 누락된 채로 기록되는 것을 방지할 수 있다.
AUTO_INCREMENT는 id와 같은 데이터를 입력하지 않아도 알아서 기존 데이터에 오름차순으로 데이터를 입력하여 기록해주는 명령어이다.
예를 들어 id가 1, 2, 3인 데이터가 테이블에 있을 때, 데이터를 새로 추가하면 추가된 데이터의 id는 자동으로 4가 된다.
VARCHAR는 CHAR형 캐릭터를 통해 데이터를 기록하는 데이터 타입이다.
TEXT는 보다 긴 텍스트를 데이터로 기록하는 데이터 타입이다.
DATETIME은 날짜와 시간을 기록하는 데이터 타입이다.
PRIMARY KEY(열 이름) 이는 해당 열의 데이터를 각 데이터들을 구분하는 가장 중요한 기준으로 생각하는 것이다.
PRIMARY KEY로 지정된 열의 데이터들은 절대 중복이 발생할 수 없다.
위 테이블에서 id 1, 2, 3인 데이터가 있을 때, id값을 2로 데이터를 추가하면 에러가 발생한다. (데이터 추가 안됨)



전체 글
133개Gradle의 dependencies에서 implementation과 compile의 차이?
https://hack-jam.tistory.com/13 [Gradle] implementation vs compile Gradle dependency 관련해서 검색을 하다보면, 어떤 글에서는 implementation을 사용하고 어떤 글에서는 compile을 사용하는 경우가 있다. 사실 어떻게 사용해도 돌아가긴 해서, 음... 무슨 차이지?하고 알아 hack-jam.tistory.com
Android Studio (모바일 프로그래밍) 2020.08.14 starmk95Retrofit(레트로핏)이란 무엇인가?
https://onlyfor-me-blog.tistory.com/141
Android Studio (모바일 프로그래밍) 2020.08.14 starmk95HTTP는 무엇인가
https://joshua1988.github.io/web-development/http-part1/
카테고리 없음 2020.08.14 starmk95JAVA)14391번 종이 조각 - 브루트 포스, 비트마스크
import java.util.*; public class Main { public static void main(String[] args) { Scanner sc = new Scanner(System.in); int n = sc.nextInt(); int m = sc.nextInt(); int[][] num = new int[n][m]; for (int i=0; i
알고리즘/백준 알고리즘(JAVA) 2020.08.12 starmk95JAVA)1182번 부분수열의 합 - 브루트포스, 비트마스크
import java.util.*; public class Main { public static void main(String[] args) { Scanner sc = new Scanner(System.in); int n = sc.nextInt(); int s = sc.nextInt(); int[] num = new int[n]; for (int i=0;i
알고리즘/백준 알고리즘(JAVA) 2020.08.12 starmk95알고리즘) 비트마스크 - 브루트 포스
# 비트마스크 - 비트 연산을 사용해서 부분집합을 표현하는 하나의 방법 # 비트 연산 and(&), or(|), not(~), xor(^) 비트연산의 시간복잡도 : O(1) cf) not의 비트연산은 자료형에 따라 결과가 달라진다. ex) 8bit 자료형, 32비트 자료형의 결과가 다르다. A = 1010011이면 ~A = 10101100 (8비트) ~A = 11111111 11111111 11111111 10101100 (32비트) # shift 비트연산 : right shift(>>), left shift(
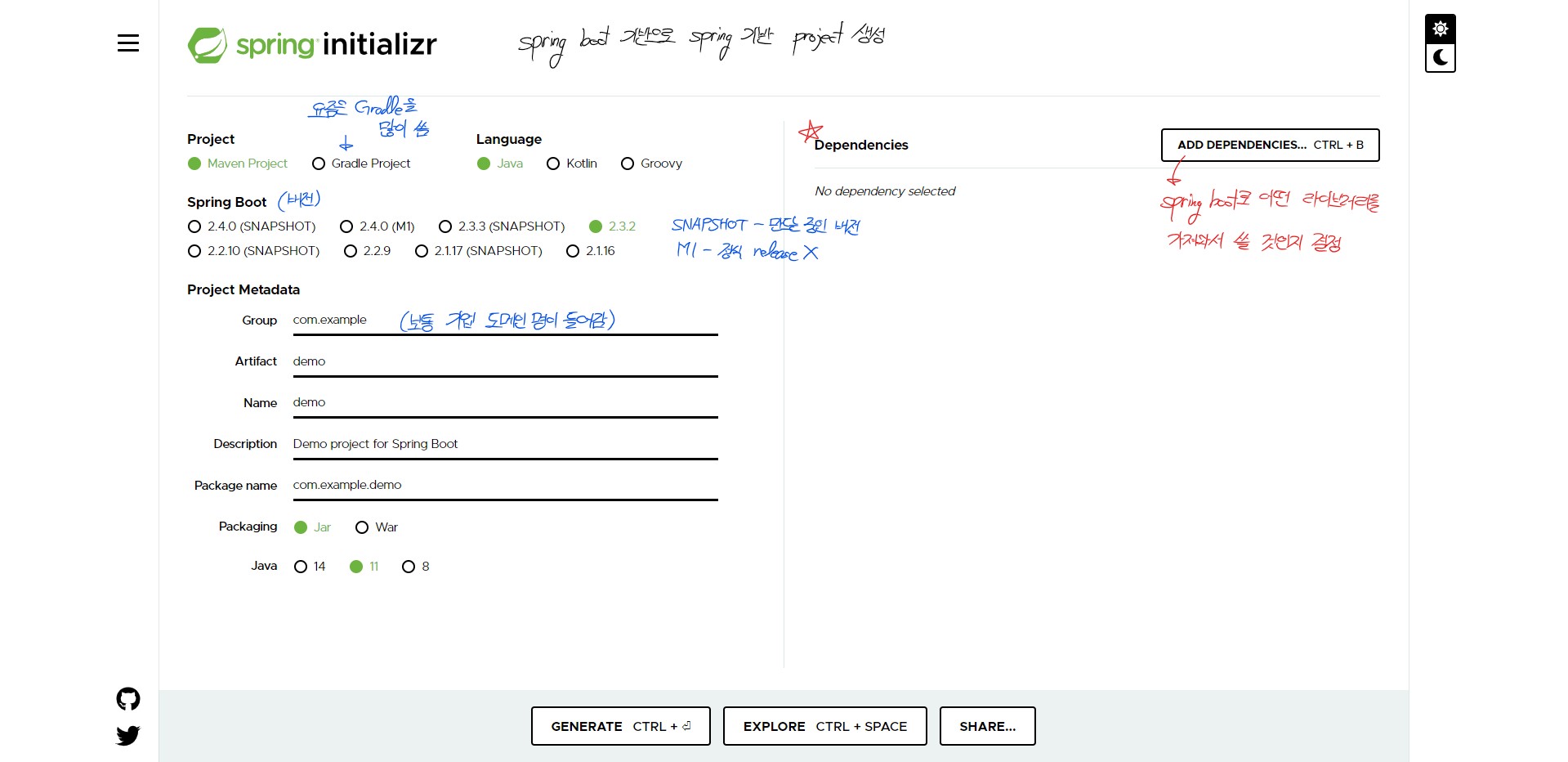
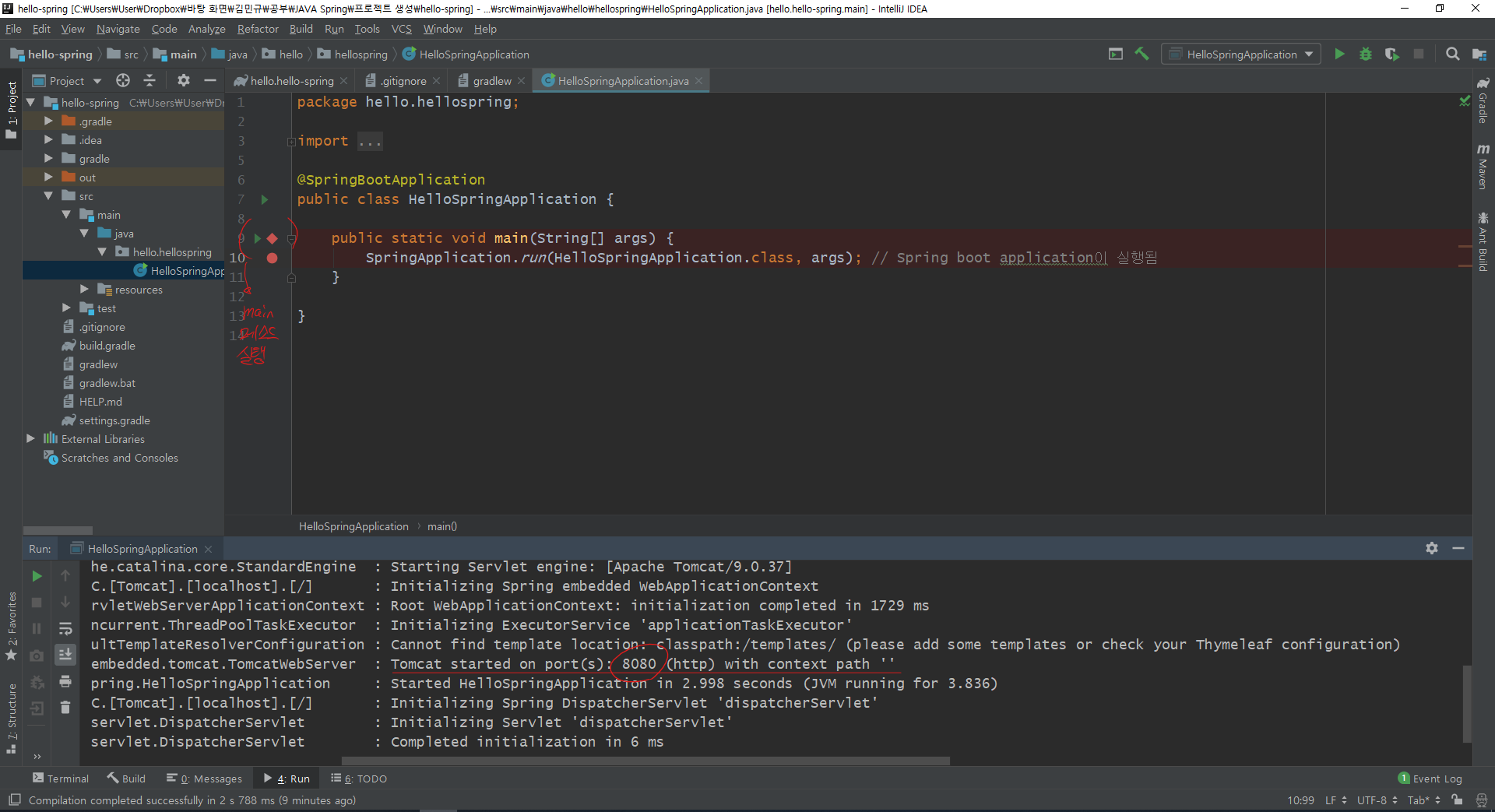
카테고리 없음 2020.08.12 starmk95JAVA Spring) 프로젝트 생성하기
0. IntelliJ 또는 Eclipse 준비, JAVA 11 버전 준비 1. Spring Boot을 통해서 프로젝트를 생성한다. https://start.spring.io/ 위 사이트로 접속해서 프로젝트에 대한 설정들을 하고 파일을 다운로드한다. 이번 예시에서는 Spring Web과 Thymeleaf 라이브러리를 가져온 프로젝트를 예로 든다. 2. 위 사이트 하단의 GENERATE 버튼을 클릭하면 압축파일이 다운로드되는데, 이 파일의 압축을 풀고, 인텔리제이에서 새 프로젝트로 import project을 통해 압축을 푼 파일 내에 build.gradle 파일을 열어서 프로젝트를 연다. 3. 생성한 프로젝트에서 main 메소드를 실행한다. 그러면 위와 같이 실행된다. 실행결과의 Tomcat 부분의 포트 ..
JAVA Spring 2020.08.10 starmk95MySQL)JOIN 명령어 - 관계형 데이터베이스의 장점 살리기
# JOIN JOIN을 통해 같은 데이터베이스 내에 존재하는 테이블들 간에 관계를 맺는 것이 가능하다. 아래 예시는 author와 topic 테이블이 있을 때, JOIN 명령어를 통해 테이블 간의 관계를 보여주는 예시이다. SELECT (선택할 열들) FROM (테이블이름1) LEFT/RIGHT JOIN (테이블이름2) ON (테이블1의 특정열) = (테이블2의 특정열); 테이블1의 선택한 열들에 대한 테이블을 LEFT라면 테이블1에 대해, RIGHT라면 테이블2에 대해 테이블2를 붙인다. 매핑하는 기준은 테이블1의 특정열과 테이블2의 특정열의 데이터 값이 같은 것끼리 연결시켜주는 것이다. JOIN하려는 테이블 간에 이름이 같은 열이 존재한다면, 사용(접근)하고자 하는 열이 어떤 테이블의 열인지 명확하게..
카테고리 없음 2020.08.09 starmk95MySQL)테이블에 데이터 추가하기, 보기 (INSERT, SELECT, UPDATE, DELETE)
SQL의 CRUD - Create, Read, Update, Delete 테이블은 만들어져 있다고 할 때, 아래와 같이 데이터를 추가해보자. 먼저 테이블이 어떤 형식으로 만들어져 있는지 확인한다. # DESC mysql> DESC topic; +-------------+--------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------------+--------------+------+-----+---------+----------------+ | id | int | NO | PRI | NULL | auto_increment | | title | varchar(100) |..
DB/MySQL 2020.08.07 starmk95MySQL)테이블 만들기
id title description created author profile 위와 같은 데이터 타입을 갖는 테이블은 CREATE TABLE topic( -> id INT(10) NOT NULL AUTO_INCREMENT, -> title VARCHAR(100) NOT NULL, -> description TEXT NULL, -> created DATETIME NOT NULL, -> author VARCHAR(15) NULL, -> profile VARCHAR(200) NULL, -> PRIMARY KEY(id) -> ); 위 코드를 통해 만들 수 있다. 각 코드별로 주석으로 설명을 달아주면 아래와 같다. CREATE TABLE topic( /* topic이라는 이름의 테이블을 만든다.*/ -> id I..
DB/MySQL 2020.08.07 starmk95MySQL)SQL의 뜻과 특징
Structured Query Language(SQL) 테이블 형식들과 같이 데이터들이 구조화됨 - Strctured 데이터베이스에 대한 여러 명령어들, 질의들 - Query 데이터베이스와 사용자가 모두 이해할 수 있는 언어 - Language SQL의 2가지 특징 1. 쉽다 2. 모든 관계형 데이터베이스는 sql을 통해 쿼리되도록 표준화되어있다. 테이블(표)에서 행 - row, record : 1개의 레코드 = 1개의 데이터 열 - column : 데이터의 타입이 무엇인지 알려준다. id name cost stock 1 MySQL \0 100 2 Oracle \1000 50 위를 하나의 테이블이라고 할 수 있다. 위 테이블에서 레코드(행)은 2개이고 이에 따라 데이터는 2개이다. 위 테이블의 4개의 열..
DB/MySQL 2020.08.07 starmk95MySQL)데이터베이스(스키마) 만들기, 제거하기, 보기, 사용하기
1. 데이터베이스(스키마) 만들기 : CREATE CREATE DATABASE opentutorials; sql문도 끝에 세미콜론 붙여줘야 함 위 명령어를 통해 opentutorials라는 이름의 스키마를 만들 수 있다. 2. 데이터베이스(스키마) 제거하기 : DROP DROP DATABASE opentutorials; 위 명령어를 통해 opentutorials라는 이름의 스키마를 제거할 수 있다. 3. 데이터베이스(스키마) 보기 : SHOW SHOW DATABASES; 위 명령어를 통해 데이터베이스 서버에 만들어져 있는 스키마들을 볼 수 있다. 출력 형식은 아래와 같다. +--------------------+ | Database | +--------------------+ | information_s..
DB/MySQL 2020.08.07 starmk95